最近在國外 AI 社群越來越常看到一個詞出現在討論串裡:Harness Engineering。
不是某個特定框架或工具,而是一種在業界逐漸成形的工程思維——描述「如何讓 AI 在系統中真正可靠地運作」。台灣這邊討論相對還少,這篇就來把它拆清楚。
問題從哪裡來
當 AI 開始從單次回答走向長流程任務,Harness Engineering 就開始變得重要。
早期大家用 AI 的方式很簡單:問一個問題、得到一個答案。這個模式下,你需要的只是一個好的 Prompt。
但現實的任務很少這麼單純。你希望 AI 幫你做的事,通常長這樣:
分析一份報告 → 整理重點 → 搜尋相關資料 → 對照比較 → 產出結論 → 如果結果不好就重新調整
這不是一次呼叫能解決的。你需要的是一套系統:讓 AI 知道任務流程、能呼叫外部工具、記住前面做了什麼、在出錯時能自動修正,還有在走偏的時候有人把它拉回來。
這套系統,就是 Harness。
還有一個重要的觀念要先建立:AI Agent 不等於單一模型。一個完整的 AI Agent,通常是多個模型加上多個工具的組合——一個模型負責理解指令、一個負責搜尋資料、一個負責評估輸出品質。Harness 就是讓這些元件能協同運作的框架。
AI 和傳統自動化的根本差異
要理解為什麼需要 Harness,先得搞清楚 AI 系統和傳統自動化在本質上哪裡不一樣。
傳統的自動化程式是 deterministic(確定性) 的:同樣的輸入,永遠得到同樣的輸出。你可以用 if/else 把所有分支都寫清楚,程式不會「發揮」。出了問題,你可以追 stack trace,每一步的行為都是可預測的。
AI 是 probabilistic(機率性) 的:同樣的輸入,每次輸出可能不同。它可以推理、可以類比、可以在沒有明確規則的情況下做出決策——但這也代表它可能輸出不符預期的結果,而且你無法完全預測它什麼時候會這樣。這不是 bug,而是模型的特性。
這就是 Harness 存在的核心理由:不是假設 AI 每次都對,而是設計一套它輸出不夠好時能夠自動修正的機制。
傳統自動化的思維是:「我把所有情況都考慮到了,所以系統不會出錯。」 Harness 的思維是:「AI 一定會有出乎意料的情況,所以我設計一套能從錯誤中恢復的系統。」
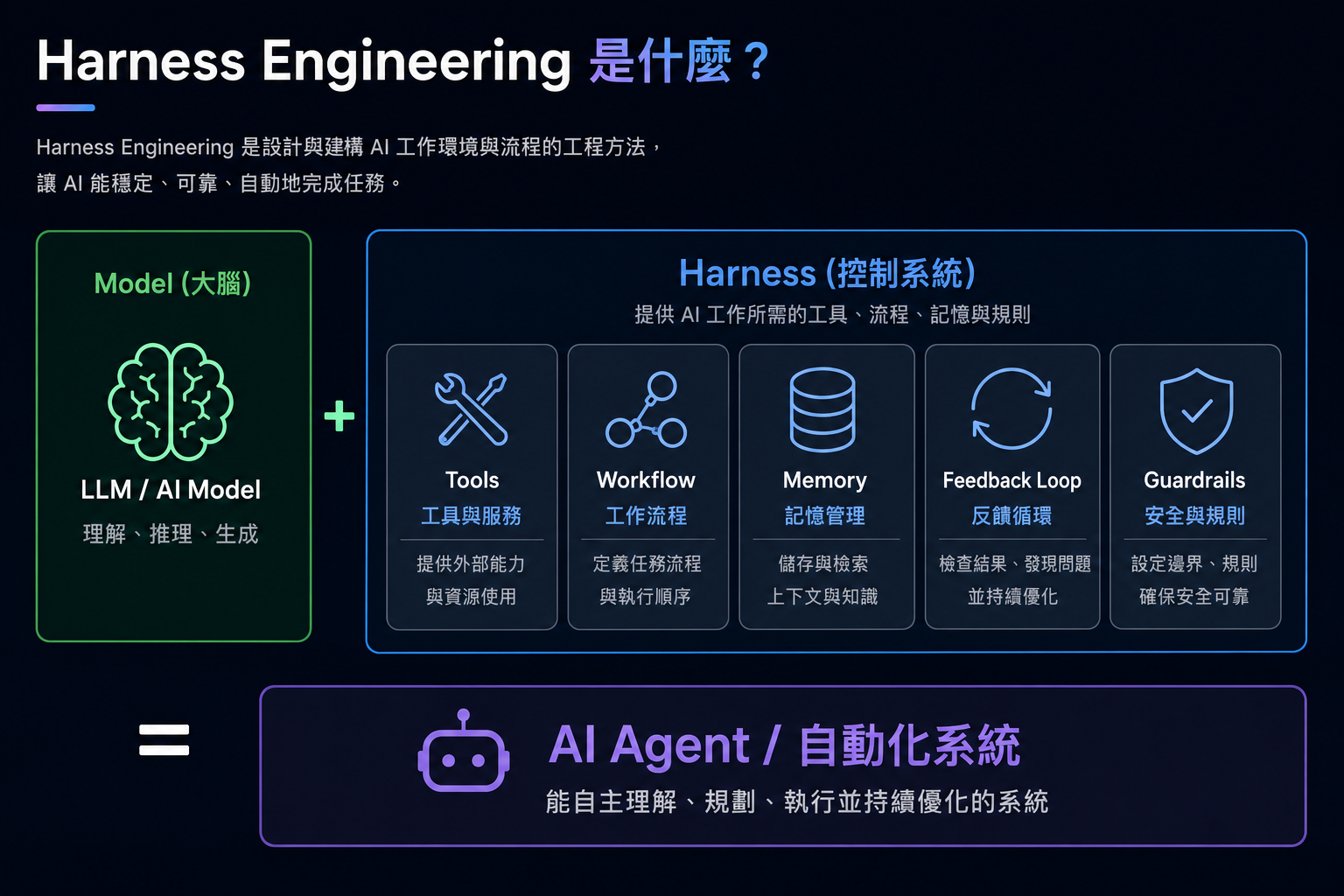
Harness Engineering 是什麼
把 AI 模型包起來,提供它工作所需的工具、流程、記憶與護欄,讓它能跨多個步驟、可靠地完成複雜任務——這套協調與調度系統就是 Harness。
Harness 是 AI 系統的 orchestration layer:負責調度模型呼叫、管理工具執行、追蹤任務狀態,讓整個流程從輸入到輸出能可靠地跑完。
從 Prompt 到 Harness:三個思考層次
Harness Engineering 不是憑空冒出來的,它是業界對「怎麼用好 AI」這個問題,需求越來越複雜之後,一步一步被逼出來的演進。
Prompt Engineering(2023)是起點。AI 變得可用,大家第一個問題是「怎麼問才能得到好答案」——措辭、結構、範例,讓單次輸出更準確。但問題很快就出現了:就算 Prompt 寫得再好,一旦任務需要多步驟,這個框架就不夠用了。
Context Engineering(2024)是第二步。你發現 AI 的輸出品質不只取決於怎麼問,更取決於它拿到了什麼資訊——背景資料、對話歷史、可用工具清單、任務規則。「垃圾進、垃圾出」的問題在這個階段最明顯,Context Engineering 的目標就是讓進去的資訊品質夠好,讓 AI 能做出正確決策。
Harness Engineering(現在)是第三步,也是目前最完整的框架。光是輸入端做好還不夠,系統整體能不能跑通才是問題:任務怎麼串、中間狀態怎麼管理、出錯了怎麼自動修正、危險的操作怎麼擋下來。
| 維度 | Prompt Engineering | Context Engineering | Harness Engineering |
|---|---|---|---|
| 關注點 | 問法夠不夠好 | 給 AI 的資訊品質 | 整套系統能不能穩定跑 |
| 核心產出 | 精準的 Prompt | 高品質的輸入脈絡 | 可自動執行、可重複的 AI 系統 |
| 視角 | 輸入端 | 資訊品質端 | 系統端 |
| 解決的問題 | 單次輸出不夠準確 | AI 缺乏足夠的背景資訊 | 流程不穩定、無法從錯誤中恢復 |
三者是層疊關係,不是替代關係:好的 Harness 系統裡,Prompt 和 Context 都要做好。
Harness 的五個核心元件
Tools(工具層)
LLM 本身不具備 side effects——它只能讀取輸入、產生輸出,無法主動和外部世界互動。Tools 層就是解決這個問題:把 AI 的決策意圖轉換成實際的外部操作。
- 呼叫外部 API(搜尋網路、查資料庫、打第三方服務)
- 讀寫檔案、操作瀏覽器
- 執行程式碼
- 呼叫其他 AI 模型
沒有 Tools,AI 只能生成文字。有了 Tools,AI 才能對真實系統產生影響。
Workflow(狀態協調層)
多個模型和工具要協同完成一個任務,就需要有人管理執行順序和中間狀態——這就是 Workflow 的職責。
Workflow 不只是「定義步驟 A 接 B」,它還要處理:目前跑到哪一步、上一步的輸出是什麼、接下來要呼叫哪個工具、如果某一步失敗了要怎麼處理。
使用者輸入 → 分析意圖 → 選擇工具 → 執行 → 驗證結果 → 輸出
這種跨模型、跨工具的狀態協調能力,是 Workflow 最核心的價值。
Guardrails(全域控制層)
Guardrails 和其他元件不太一樣——它不是一個執行步驟,而是貫穿整個任務的全域控制層,在任何時間點都能介入:
- 輸入過濾:阻擋惡意提示注入(prompt injection)
- 輸出審核:確保回答符合規範,不輸出有害內容
- 行動限制:禁止刪除資料、禁止發送特定訊息
- 成本控管:限制單次 token 用量、呼叫頻率,避免費用失控
設計 Guardrails 的思維是:你不是在限制 AI 的能力,而是在定義一個安全的操作邊界。
Memory(記憶層)
每次 LLM 呼叫預設是無狀態的,Memory 層解決這個問題。
實際工程中,Memory 有兩個用途:
短期記憶(當次任務):把這次任務執行到哪、呼叫了哪些工具、出了什麼錯,放進下一次呼叫的 context 裡。這讓 AI 在多步驟任務中保持連貫,不會每一步都像第一次見面。
長期記憶(跨任務):把成功的提示詞策略、常見的失敗模式、特定場景的最佳做法記下來,下次執行同類任務時直接作為參考。久了以後,系統會越來越「有經驗」——同樣的問題不用再重新摸索。
Memory 在 Feedback Loop 裡扮演的角色尤其關鍵:沒有 Memory,每次 Retry 都等於從零開始;有了 Memory,每次 Retry 都是在上一次的基礎上優化。
Feedback Loop:AI 系統必須能從錯誤中恢復
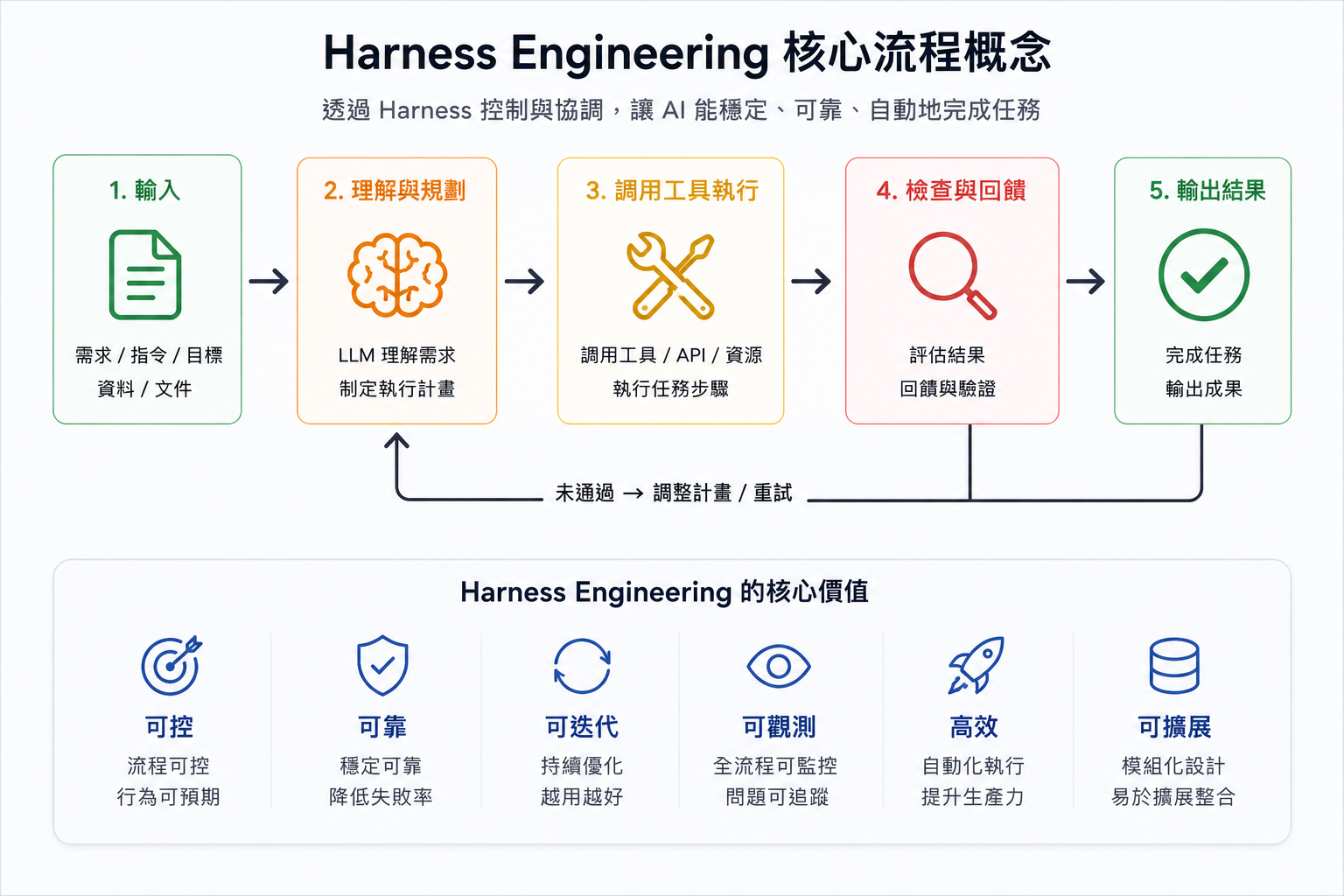
這是 Harness 和傳統自動化差距最大的地方,也是整個框架的核心設計。
傳統自動化假設「只要邏輯正確,結果就會正確」。AI 系統不能這樣假設——因為模型的輸出本質上是機率性的,在沒有 Retry 機制的情況下,你其實是在賭每次輸出都剛好夠好。
AI 系統需要的不是「避免出錯」,而是「有計畫地從輸出品質不足中恢復」。
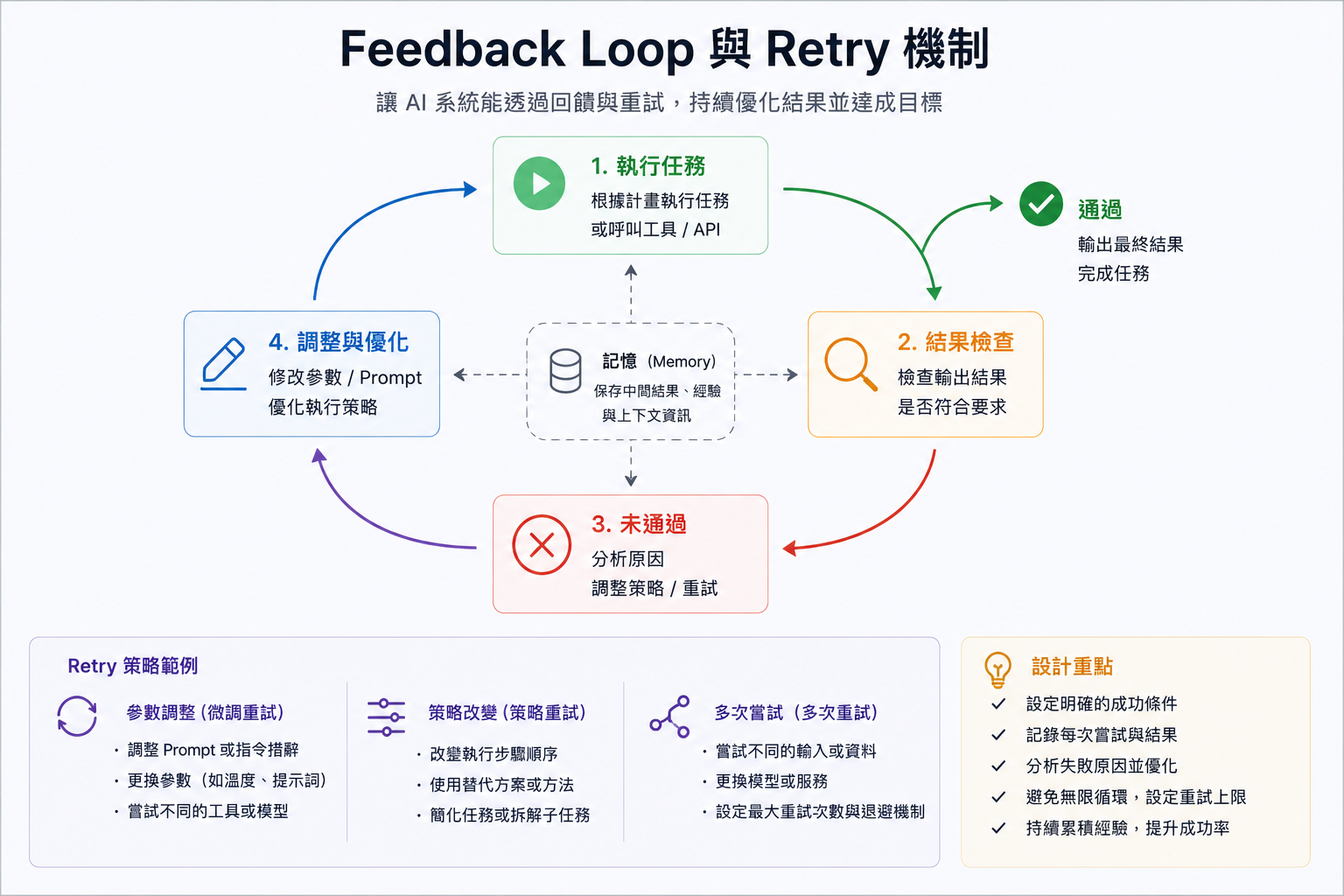
整個迴圈是這樣運作的:
- 執行任務:根據計畫執行,呼叫工具或 API
- 結果檢查:檢查輸出是否符合要求(可以用規則判斷,也可以用另一個 LLM 評分)
- 未通過 → 調整:分析失敗原因,調整 Prompt 措辭、更換工具、拆解子任務
- 重試:帶著調整後的策略重新執行,直到通過或達到重試上限
Memory 在中間是關鍵:每一輪的執行結果和失敗原因都被記下來,讓下一輪 Retry 不是盲目重試,而是有依據的優化。
實際案例:Ollama + ComfyUI 的圖像生成 Pipeline
Feedback Loop 最直觀的例子,是用本地模型做圖像生成的自動化迴圈。
整個 Pipeline 的結構長這樣:
[使用者輸入:角色描述]
↓
[Ollama LLM:將描述轉換成詳細的 Stable Diffusion 提示詞]
↓
[ComfyUI API:根據提示詞生成圖像]
↓
[Ollama Vision Model:評估圖像品質——構圖、細節、符不符合描述]
↓
[品質未通過?]
→ Memory 記錄失敗原因(例如:手部細節不自然、服裝顏色偏差)
→ 調整提示詞,針對問題強化描述
→ 重新生成,最多重試 3 次
↓
[通過 → 輸出最終圖像]
這個迴圈裡有三個模型協同工作:一個負責語言理解、一個負責圖像生成、一個負責視覺評估。Harness 就是讓這三個模型能串接起來、狀態能傳遞下去、失敗能自動修正的那一層。
評估不過就輸出「當前最佳候選」,而不是一直重試——重試上限設 2~3 次,讓系統在效能和品質之間取得平衡,使用者體感也會好很多。
這個架構的應用方向很廣:角色生成、電商商品圖、服裝搭配視覺化——只要是「需要反覆產出圖像、並評估品質」的場景,都可以套用類似的 Harness Pipeline。
可觀測性:你必須知道系統在做什麼
Harness 系統面對的一個特殊挑戰:AI workflow 的 debug 比傳統程式難得多。
傳統程式出問題,你看 stack trace、看 log,通常能定位到具體的一行。AI 系統出問題,可能的原因有很多:Prompt 措辭不夠精確、Context 裡缺少關鍵資訊、工具回傳了非預期格式、或者這次模型的輸出方向剛好偏了。這些問題沒有固定的發生位置,也沒有 stack trace 可以追。
這代表 Harness 系統從一開始就需要把可觀測性(Observability)設計進去,而不是事後補:
- 每一次 LLM 呼叫都要 logging:完整記錄輸入的 prompt、輸出的內容、token 用量、呼叫時間
- 每一次 Retry 的原因都要記錄:是哪個檢查沒通過、失敗的具體描述是什麼
- 任務的整體 trace 要能還原:能看到整個任務從開始到結束每一步做了什麼、狀態如何轉移
沒有這些,Harness 系統就是一個黑盒子。跑得順的時候你不知道為什麼順,出問題的時候也不知道從哪裡開始找。
Harness 是一種新的 AI 系統設計思維
Harness Engineering 的核心問題意識很簡單:「模型夠聰明」和「系統夠可靠」是兩件事。
選一個更強的模型,不代表你的 AI 系統就更穩定。穩定來自系統設計——你怎麼管理狀態、怎麼處理失敗、怎麼讓不同模型和工具協同工作、怎麼確保整個流程在預期的邊界內運作。
這是傳統軟體工程師很熟悉的問題框架,只是換了一個更不確定的執行層:LLM。
Harness 不是一個你必須一次就建得很完整的東西。從一個最簡單的 Retry Loop 開始——先讓「執行 → 檢查 → 不夠好就調整重試」這個基本機制跑起來,就已經是 Harness 思維的實踐了。Memory、完整的 Workflow、Observability,這些都可以隨著系統複雜度慢慢疊加。
AI 模型負責推理,Harness 負責讓推理結果能在真實系統中、跨多個步驟、可靠地落地。 這件事,沒有辦法只靠一個好的 Prompt 解決。